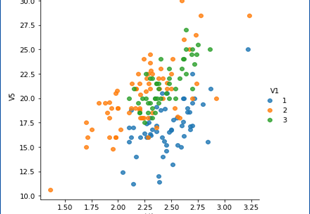
Ivan Muhammad SiegfriedUnderstanding Naive-Bayes ClassifierStatistical Basis4 min read·Apr 15, 2021----
Ivan Muhammad SiegfriedThe Framework Process of Data Science: Cross-industry Standard Process for Data Mining (CRISP-DM)Introduction8 min read·Apr 15, 2021----
Ivan Muhammad SiegfriedSinking Kafka Topic to MongoDB using PymongoIntroduction2 min read·Apr 10, 2021----
Ivan Muhammad SiegfriedUsing Python (Jupyter Notebook) as Kafka ProducerOn this occasion, I will explain the use of Python scripts to produce data for Kafka Producer using a fake pizza-based dataset to then be…3 min read·Apr 8, 2021----